Publications
2026

Orthographer: Generating Orthographic-Style Projections for Elongated Architectural Structures CV IM AI
Yu-Hsuan Hsieh, Yu-Ting Wu
Computer Graphics Forum, to appear
show / hide abstract ...
Photographing architecturally expansive structures presents significant challenges due to the limited field of view inherent to standard imaging systems. Traditional solutions, including the use of wide-angle optics or panoramic stitching techniques, frequently introduce significant geometric distortions that compromise the fidelity of architectural forms. To address this limitation, we introduce a novel framework for synthesizing orthographic-style projections of elongated buildings, with an emphasis on structural preservation. The proposed method leverages a neural semantic segmentation network to autonomously identify architectural components and foreground elements within a panoramic image. Geometric rectification is performed via a forward mapping algorithm, derived from extracted boundary contours and vanishing point estimations, and is complemented by an inpainting stage to recover missing regions. Empirical evaluations confirm that our pipeline maintains architectural accuracy more effectively than conventional techniques, while offering an accessible and streamlined image acquisition process.
Enhanced 360-Degree Panorama Synthesis: Leveraging Smartphone Sensors and Semantic-Driven Neural Architecture CV IM AI
Yu-Wen Liu, Nien-Hsin Tseng, Hsin-Chang Yu, Yu-Ting Wu
Journal of Information Science and Engineering (JISE), to appear
show / hide abstract ...
360-degree imagery offers immersive multimedia experiences but remains challenging for non-experts to acquire. This paper introduces a novel framework for synthesizing high-fidelity 360-degree panoramas from partial panoramas constructed from arbitrary normal-field-of-view (NFoV) images. Our method leverages inertial and orientation data from smartphone sensors to infer spatial configurations, enabling flexible image capture. To improve synthesis quality, we propose a saliency-aware view selection strategy that reduces the discrepancy between synthesized training data and inference-time inputs. Additionally, we introduce a data augmentation technique, termed circular padding, and integrate it into a semantics-guided NFoV outpainting framework to extend its capability to 360-degree panoramic synthesis while preserving boundary continuity. Both quantitative and qualitative results show that our method produces panoramas with superior visual realism and structural coherence compared to existing learning-based approaches.
2025

Preserving Photographic Defocus in Stylised Image Synthesis CV IM AI
Hong-Yi Wang, Yu-Ting Wu
Computer Graphics Forum, to appear
show / hide abstract ...
While style transfer has been extensively studied, most existing approaches fail to account for the defocus effects inherent in content images, thereby compromising the photographer's intended focus cues. To overcome this shortcoming, we introduce an optimisation-based post-processing framework that restores defocus characteristics to stylised images, regardless of the style transfer technique used. Our method initiates by estimating a blur map through a data-driven model that predicts pixel-level blur magnitudes. This blur map subsequently guides a layer-based defocus rendering framework, which effectively simulates depth-of-field (DoF) effects using a Gaussian filter bank. To map the blur values to appropriate kernel sizes in the filter bank, we introduce a neural network that determines the optimal maximum filter size, ensuring both content integrity and stylistic fidelity. Experimental results, both quantitative and qualitative, show that our method significantly improves stylised images by preserving the original depth cues and defocus details.

Efficient Stereo-Aware Screen-Space Ambient Occlusion with Adaptive Computation XR CG
Yu-Ting Wu
IEEE Computer Graphics and Applications (CG&A), to appear
show / hide abstract ...
Screen-space ambient occlusion (SSAO) has become a widely used technique in real-time rendering, valued for its high performance and full support for dynamic geometry. However, applying SSAO directly to stereo rendering can result in incorrect depth perception and viewer discomfort due to differences in captured scene approximations between the left and right views. Existing methods for generating stereo-consistent SSAO often involve substantial computational costs. This paper introduces an adaptive rendering framework, inspired by Weber’s law, to achieve stereo-consistent SSAO more efficiently. Our method identifies the inconsistent pixels generated by monoscopic SSAO algorithms and applies computationally intensive stereo-aware computations only to those pixels. Experiments demonstrate that our method delivers stereo-consistent results comparable to state-of-the-art techniques while significantly enhancing rendering performance.

Efficient Environment Map Rendering Based on Decomposition CG XR
Yu-Ting Wu
Computer Graphics Forum, February 2025
show / hide abstract ...
This paper presents an efficient environment map sampling algorithm designed to render high-quality, low-noise images with only a few light samples, making it ideal for real-time applications. We observe that bright pixels in the environment map produce high-frequency shading effects, such as sharp shadows and shading, while the rest influence the overall tone of the scene. Building on this insight, our approach differs from existing techniques by categorizing the pixels in an environment map into emissive and non-emissive regions and developing specialized algorithms tailored to the distinct properties of each region. By decomposing the environment lighting, we ensure that light sources are deposited on bright pixels, leading to more accurate shadows and specular highlights. Additionally, this strategy allows us to exploit the smoothness in the low-frequency component by rendering a smaller image with more lights, thereby enhancing shading accuracy. Extensive experiments demonstrate that our method significantly reduces shadow artifacts and image noise compared to previous techniques, while also achieving lower numerical errors across a range of illumination types, particularly under limited sample conditions.
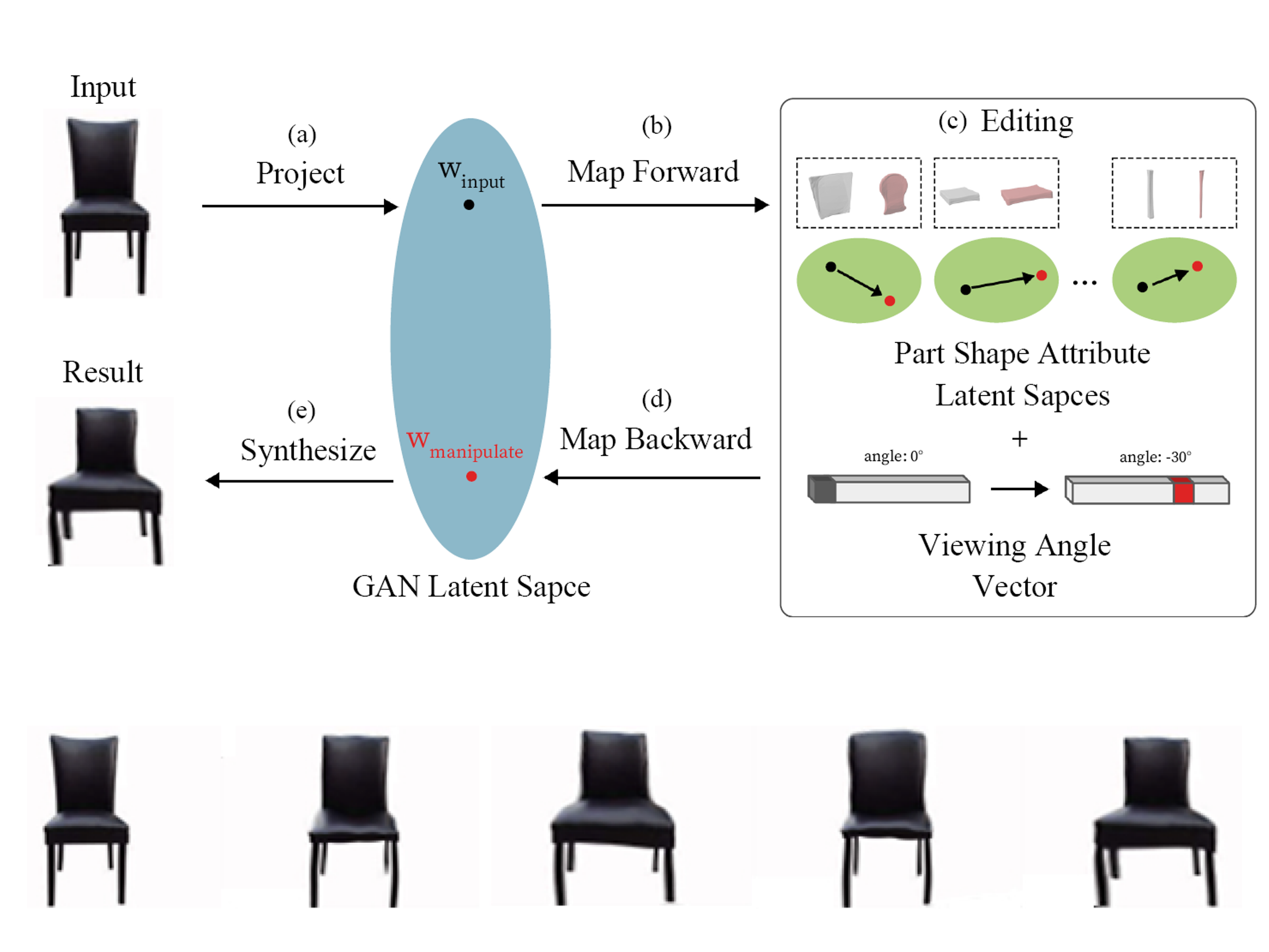
StylePart: Image-based Shape Part Manipulation CV IM AI
I-Chao Shen, Li-Wen Su, Yu-Ting Wu, Bing-Yu Chen
The Visual Computer, January 2025
show / hide abstract ...
Direct part-level manipulation of man-made shapes in an image is desired given its simplicity. However, it is not intuitive given the existing manually created cuboid and cylinder controllers. To tackle this problem, we present StylePart, a framework that enables direct shape manipulation of an image by leveraging generative models of both images and 3D shapes. Our key contribution is a shape-consistent latent mapping function that connects the image generative latent space and the 3D man-made shape attribute latent space. Our method “forwardly maps” the image content to its corresponding 3D shape attributes, where the shape part can be easily manipulated. The attribute codes of the manipulated 3D shape are then “backwardly mapped” to the image latent code to obtain the final manipulated image. By using both forward and backward mapping, an user can edit the image directly without resorting to any 3D workflow. We demonstrate our approach through various manipulation tasks, including part replacement, part resizing, and shape orientation manipulation, and evaluate its effectiveness through extensive ablation studies.
2024

Improving Cache Placement for Efficient Cache-based Rendering CG
Yu-Ting Wu, I-Chao Shen
The Visual Computer, November 2024
show / hide abstract ...
This paper proposes a new method to improve cache placement for various rendering algorithms using caching techniques. The proposed method comprises two stages. The first stage computes an initial cache distribution based on shading points’ geometric proximity. We present a view-guided method to cluster shading points based on their world-space positions and surface normals, while considering the camera view to avoid producing small clusters in the final image. The proposed method is more robust and easier to control than previous shading point clustering methods. After computing the shading functions at the initial cache locations, the second stage of our method utilizes the results to allocate additional caches to regions with shading discontinuities. To achieve this, a discontinuity map is created to identify these regions and used to insert new caches based on importance sampling. We integrate the proposed method into several cache-based algorithms, including irradiance caching, importance caching, and ambient occlusion. Extensive experiments show that our method outperforms other cache distributions, producing better results both numerically and visually.
2023

360MVSNet: Deep Multi-view Stereo Network with 360° Images for Indoor Scene Reconstruction CV AI
Ching-Ya Chiu, Yu-Ting Wu, I-Chao Shen, Yung-Yu Chuang
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2023
show / hide abstract ...
Recent multi-view stereo methods have achieved promising results with the advancement of deep learning techniques. Despite of the progress, due to the limited fields of view of regular images, reconstructing large indoor environments still requires collecting many images with sufficient visual overlap, which is quite labor-intensive. 360° images cover a much larger field of view than regular images and would facilitate the capture process. In this paper, we present 360MVSNet, the first deep learning network for multi-view stereo with 360° images. Our method combines uncertainty estimation with a spherical sweeping module for 360° images captured from multiple viewpoints in order to construct multi-scale cost volumes. By regressing volumes in a coarse-to-fine manner, high-resolution depth maps can be obtained. Furthermore, we have constructed EQMVS, a large-scale synthetic dataset that consists of over 50K pairs of RGB and depth maps in equirectangular projection. Experimental results demonstrate that our method can reconstruct large synthetic and real-world indoor scenes with significantly better completeness than previous traditional and learning-based methods while saving both time and effort in the data acquisition process.
2022

StyleFaceUV: a 3D Face UV Map Generator for View-Consistent Face Image Synthesis CV CG AI
Wei-Chieh Chung*, Jian-Kai Zhu*, I-Chao Shen, Yu-Ting Wu, Yung-Yu Chuang (*: joint first authors)
British Machine Vision Conference (BMVC) 2022
show / hide abstract ...
Recent deep image generation models, such as StyleGAN2, face challenges to produce high-quality 2D face images with multi-view consistency. We address this issue by proposing an approach for generating detailed 3D faces using a pre-trained StyleGAN2 model. Our method estimates the 3D Morphable Model (3DMM) coefficients directly from the StyleGAN2’s stylecode. To add more details to the produced 3D face models, we train a generator to produce two UV maps: a diffuse map to give the model a more faithful appearance and a generalized displacement map to add geometric details to the model. To achieve multi-view consistency, we also add a symmetric view image to recover information regarding the invisible side of a single image. The generated detailed 3D face models allow for consistent changes in viewing angles, expressions, and lighting conditions. Experimental results indicate that our method outperforms previous approaches both qualitatively and quantitatively.
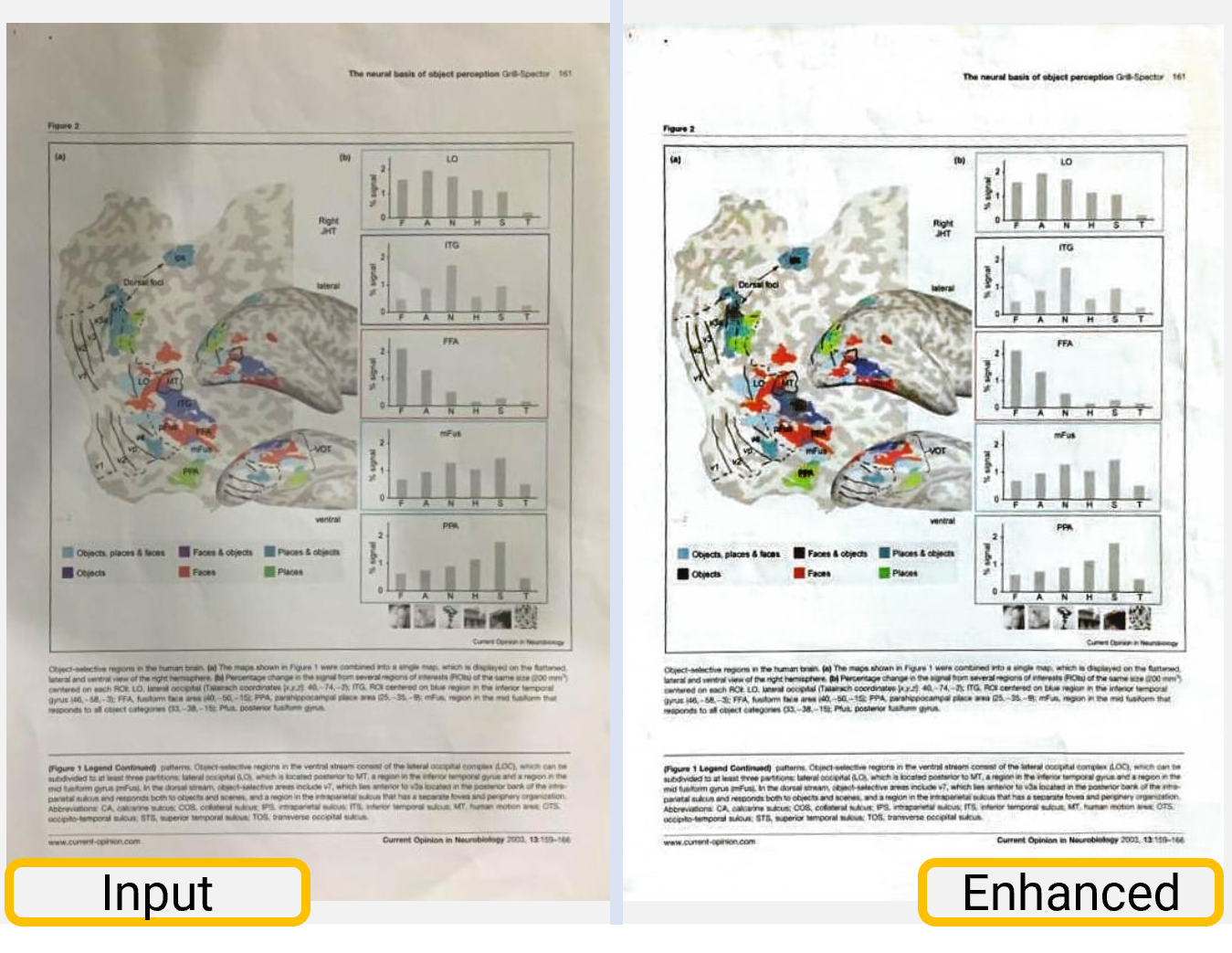
ScannerNet: A Deep Network for Scanner-Quality Document Images under Complex Illumination CV IM AI
Chih-Jou Hsu, Yu-Ting Wu, Ming-Sui Lee, Yung-Yu Chuang
British Machine Vision Conference (BMVC) 2022
show / hide abstract ...
Document images captured by smartphones and digital cameras are often subject to photometric distortions, including shadows, non-uniform shading, and color shift due to the imperfect white balance of sensors. Readers are confused by an indistinguishable background and content, which significantly reduces legibility and visual quality. Despite the fact that real photographs often contain a mixture of these distortions, the majority of existing approaches to document illumination correction concentrate on only a small subset of these distortions. This paper presents ScannerNet, a comprehensive method that can eliminate complex photometric distortions using deep learning. In order to exploit the different characteristics of shadow and shading, our model consists of a sub-network for shadow removal followed by a sub-network for shading correction. To train our model, we also devise a data synthesis method to efficiently construct a large-scale document dataset with a great deal of variation. Our extensive experiments demonstrate that our method significantly enhances visual quality by removing shadows and shading, preserving figure colors, and improving legibility.
2021

Learning to Cluster for Rendering with Many Lights CG AI
Yu-Chen Wang, Yu-Ting Wu, Tzu-Mao Li, Yung-Yu Chuang
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2021), December 2021
show / hide abstract ...
We present an unbiased online Monte Carlo method for rendering with many lights. Our method adapts both the hierarchical light clustering and the sampling distribution to our collected samples. Designing such a method requires us to make clustering decisions under noisy observation, and making sure that the sampling distribution adapts to our target. Our method is based on two key ideas: a coarse-to-fine clustering scheme that can find good clustering configurations even with noisy samples, and a discrete stochastic successive approximation method that starts from a prior distribution and provably converges to a target distribution. We compare to other state-of-the-art light sampling methods, and show better results both numerically and visually.

Multi-Resolution Shared Representative Filtering for Real-Time Depth Completion CG CV IM
Yu-Ting Wu, Tzu-Mao Li, I-Chao Shen, Hong-Shiang Lin, Yung-Yu Chuang
High-Performance Graphics (HPG) 2021
show / hide abstract ...
We present shared representative filtering for real-time high-resolution depth completion with RGB-D sensors. Conventional filtering-based methods face a dilemma when the missing regions of the depth map are large. When the filter window is small, the filter fails to include enough samples. On the other hand, when the window is large, the method could oversmooth depth boundaries due to the error introduced by the extra samples. Our method adapts the filter kernels to the shape of the missing regions to collect a sufficient number of samples while avoiding oversmoothing. We collect depth samples by searching for a small set of similar pixels, which we call the representatives, using an efficient line search algorithm. We then combine the representatives using a joint bilateral weight. Experiments show that our method can filter a high-resolution depth map within a few milliseconds while outperforming previous filtering-based methods on both real-world and synthetic data in terms of both efficiency and accuracy, especially when dealing with large missing regions in depth maps.
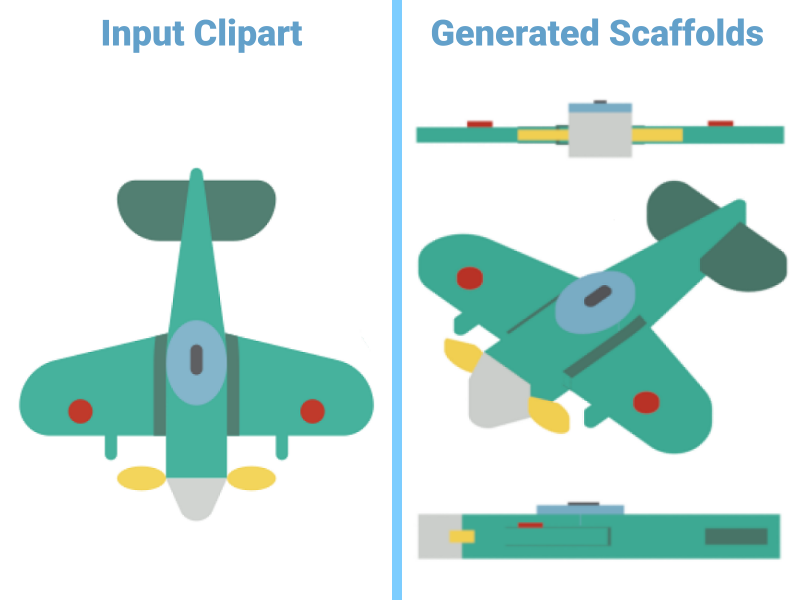
ClipFlip: Multi-view Clipart Design CG CV AI
I-Chao Shen, Kuan-Hung Liu, Li-Wen Su, Yu-Ting Wu, Bing-Yu Chen
Computer Graphics Forum, February 2021
show / hide abstract ...
We present an assistive system for clipart design by providing visual scaffolds from the unseen viewpoints. Inspired by the artists’ creation process, our system constructs the visual scaffold by first synthesizing the reference 3D shape of the input clipart and rendering it from the desired viewpoint. The critical challenge of constructing this visual scaffold is to generate a reference 3D shape that matches the user’s expectations in terms of object sizing and positioning while preserving the geometric style of the input clipart. To address this challenge, we propose a user-assisted curve extrusion method to obtain the reference 3D shape. We render the synthesized reference 3D shape with a consistent style into the visual scaffold. By following the generated visual scaffold, the users can efficiently design clipart with their desired viewpoints. The user study conducted by an intuitive user interface and our generated visual scaffold suggests that our system is especially useful for estimating the ratio and scale between object parts and can save on average 57% of drawing time.
2015

Dual-Matrix Sampling for Scalable Translucent Material Rendering CG
Yu-Ting Wu, Tzu-Mao Li, Yu-Hsun Lin, Yung-Yu Chuang
IEEE Transactions on Visualization and Computer Graphics (TVCG), March 2015
show / hide abstract ...
This paper introduces a scalable algorithm for rendering translucent materials with complex lighting. We represent the light transport with a diffusion approximation by a dual-matrix representation with the Light-to-Surface and Surface-to-Camera matrices. By exploiting the structures within the matrices, the proposed method can locate surface samples with little contribution by using only subsampled matrices and avoid wasting computation on these samples. The decoupled estimation of irradiance and diffuse BSSRDFs also allows us to have a tight error bound, making the adaptive diffusion approximation more efficient and accurate. Experiments show that our method outperforms previous methods for translucent material rendering, especially in large scenes with massive translucent surfaces shaded by complex illumination.
2014

Sampling and Reconstruction Techniques for Efficient Monte Carlo Rendering CG
Yu-Ting Wu, advised by Yung-Yu Chuang
Doctor of Philosophy in Computer Science and Information Engineering, National Taiwan University, June 2014
show / hide abstract ...
Two of the most important tasks that computer graphics techniques try to solve is rendering photo-realistic images and performing numerically accurate simulation. Physically-based rendering can naturally satisfy these two goals. It is usually simulated by the Monte Carlo ray tracing for handling a variety of sophisticated light transport paths in a united manner. Despite its generality and simplicity, however, Monte Carlo integration converges slowly. Rendering scenes with lots of complex geometry and realistic materials under complex illumination usually requires a large number of samples to produce a noise-free image.
In this dissertation, we proposed three advanced sampling and reconstruction algorithms for improving the performance of Monte Carlo integration. First, realizing that in complex scenes visibility is usually the major source of noise during sampling the shading function, we developed a method called VisibilityCluster for efficiently approximating visibility function. By integrating it into importance sampling framework, we achieve superior noise reduction compared to previous approaches. Second, to reduce the computation overhead of rendering translucent materials, we proposed an algorithm, Dualmatrix sampling, to avoid evaluating unimportant surface samples which contribute little to the final image. Finally, a general adaptive sampling and reconstruction framework named SURE-based optimization is proposed to render a wide range of distributed effects, including depth of field, motion blur, and global illumination. All of the three methods achieve significant performance improvement compared to the state-of-the-art rendering algorithms.
2013

VisibilityCluster: Average Directional Visibility for Many-Light Rendering CG
Yu-Ting Wu, Yung-Yu Chuang
IEEE Transactions on Visualization and Computer Graphics (TVCG), September 2013
show / hide abstract ...
This paper proposes the VisibilityCluster algorithm for efficient visibility approximation and representation in many-light rendering. By carefully clustering lights and shading points, we can construct a visibility matrix that exhibits good local structures due to visibility coherence of nearby lights and shading points. Average visibility can be efficiently estimated by exploiting the sparse structure of the matrix and shooting only few shadow rays between clusters. Moreover, we can use the estimated average visibility as a quality measure for visibility estimation, enabling us to locally refine VisibilityClusters with large visibility variance for improving accuracy. We demonstrate that, with the proposed method, visibility can be incorporated into importance sampling at a reasonable cost for the manylight problem, significantly reducing variance in Monte Carlo rendering. In addition, the proposed method can be used to increase realism of local shading by adding directional occlusion effects. Experiments show that the proposed technique outperforms state-ofthe-art importance sampling algorithms, and successfully enhances the preview quality for lighting design.
2012

SURE-based Optimization for Adaptive Sampling and Reconstruction CG
Tzu-Mao Li, Yu-Ting Wu, Yung-Yu Chuang
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2012), November 2012
show / hide abstract ...
We apply Stein’s Unbiased Risk Estimator (SURE) to adaptive sampling and reconstruction to reduce noise in Monte Carlo rendering. SURE is a general unbiased estimator for mean squared error (MSE) in statistics. With SURE, we are able to estimate error for an arbitrary reconstruction kernel, enabling us to use more effective kernels rather than being restricted to the symmetric ones used in previous work. It also allows us to allocate more samples to areas with higher estimated MSE. Adaptive sampling and reconstruction can therefore be processed within an optimization framework. We also propose an efficient and memory-friendly approach to reduce the impact of noisy geometry features where there is depth of field or motion blur. Experiments show that our method produces images with less noise and crisper details than previous methods.
